MRZ (Machine Readable Zone)¶
Formats¶
MRZ / MRTD (Machine Readable Zone / Travel Documents) format is standardized by the ICAO (International Organization for Standardization) in Document 9303. The document is divided in 7 parts:
Fortunately you don’t need to read all these documents to understand the MRZ / MRTD format our use our SDK. We have done the work for you.
There are 3 main formats: TD1, TD2, TD3 and Visas (MRVA and MRVB).
TD1¶
This format is defined in Machine Readable Travel Documents Part 5: Specifications for TD1 Size Machine Readable Official Travel Documents (MROTDs) document.
Here is a sample image:

Here is the format:

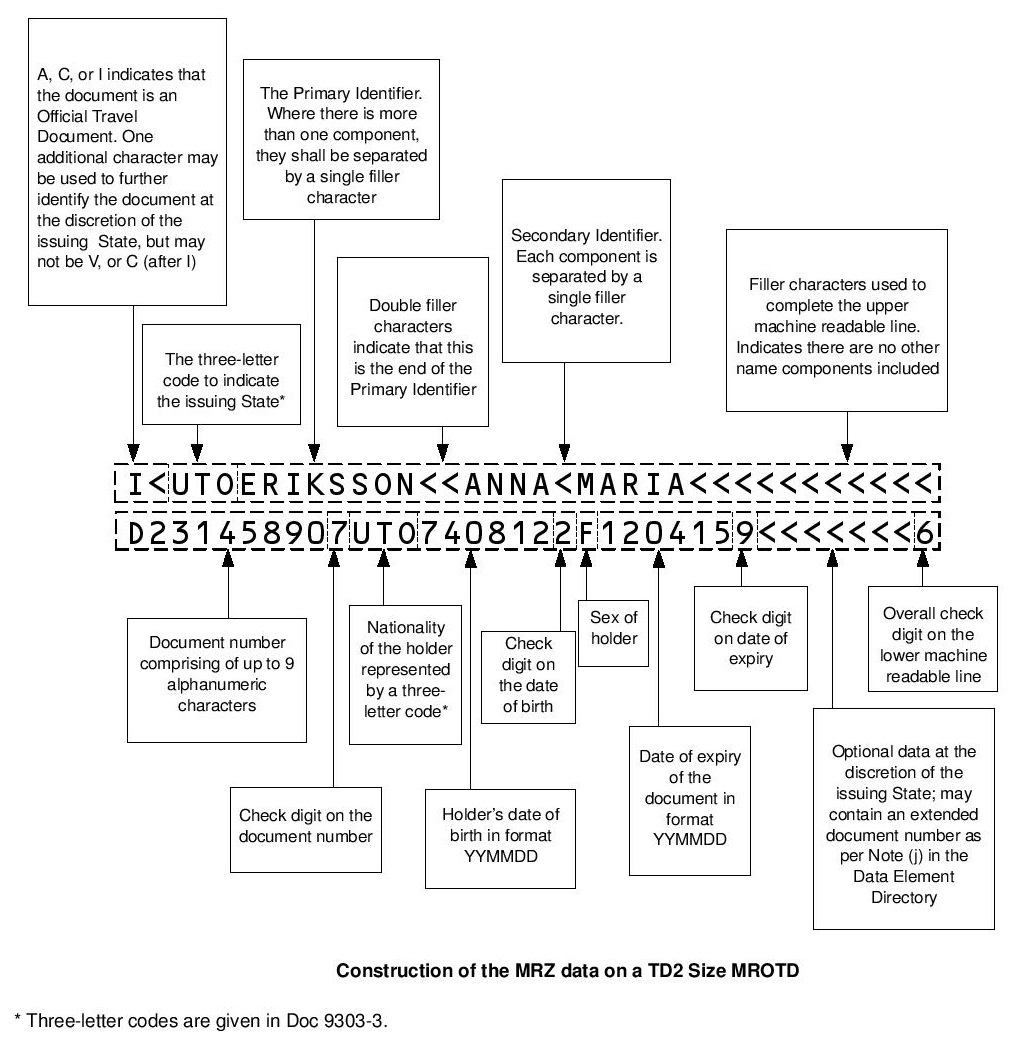
TD2¶
This format is defined in Machine Readable Travel Documents Part 6: Specifications for TD2 Size Machine Readable Official Travel Documents (MROTDs) document.
Here is a sample image:

Here is the format:
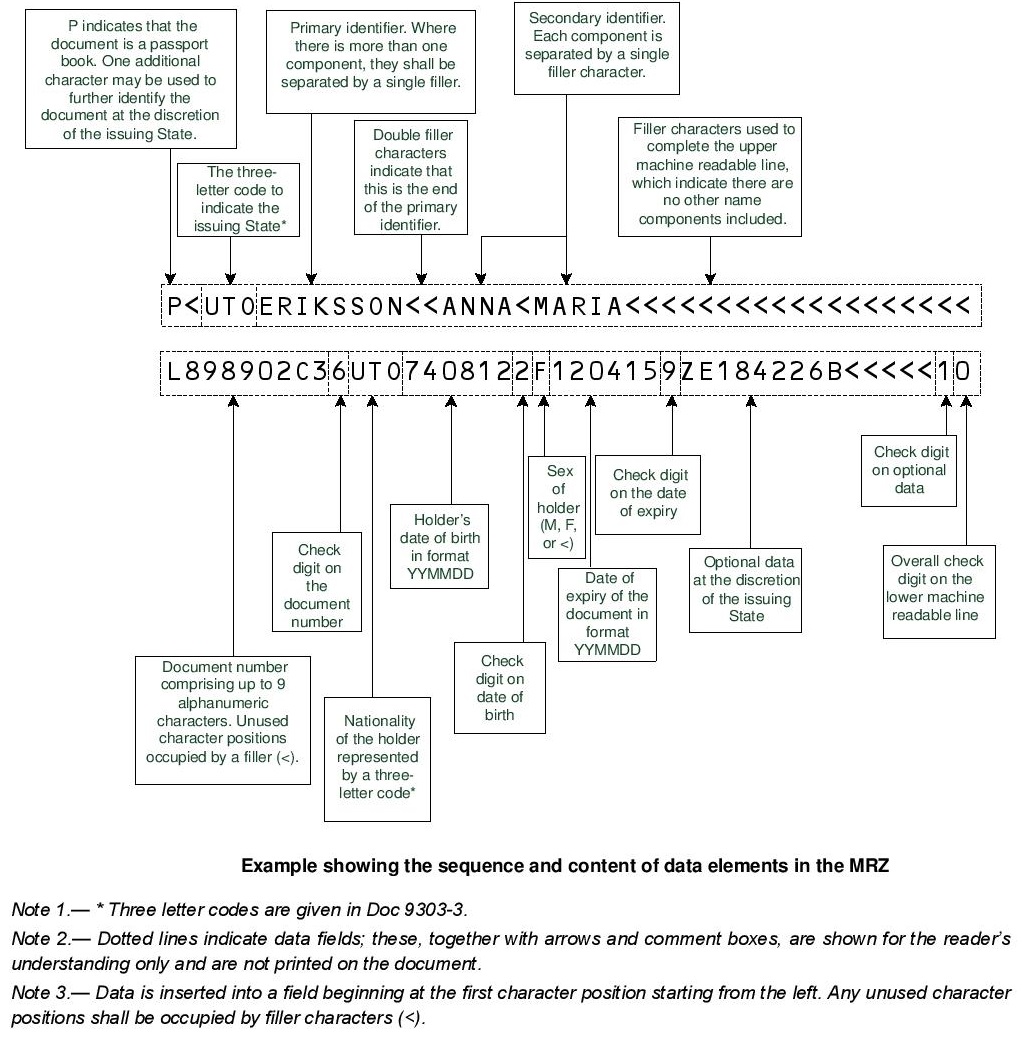
TD3¶
This format is defined in Machine Readable Travel Documents Part 4: Specifications for Machine Readable Passports (MRPs) and other TD3 Size MRTDs document.
Here is a sample image:

Here is the format:

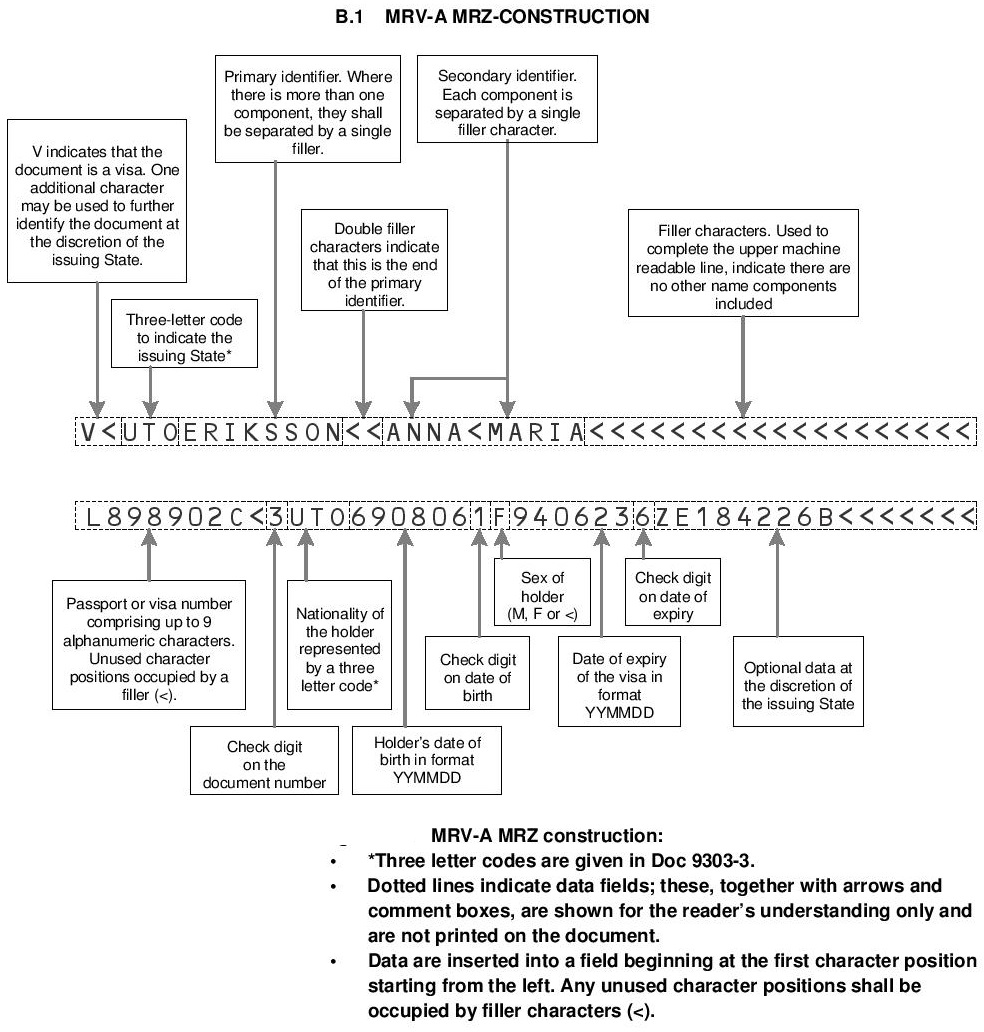

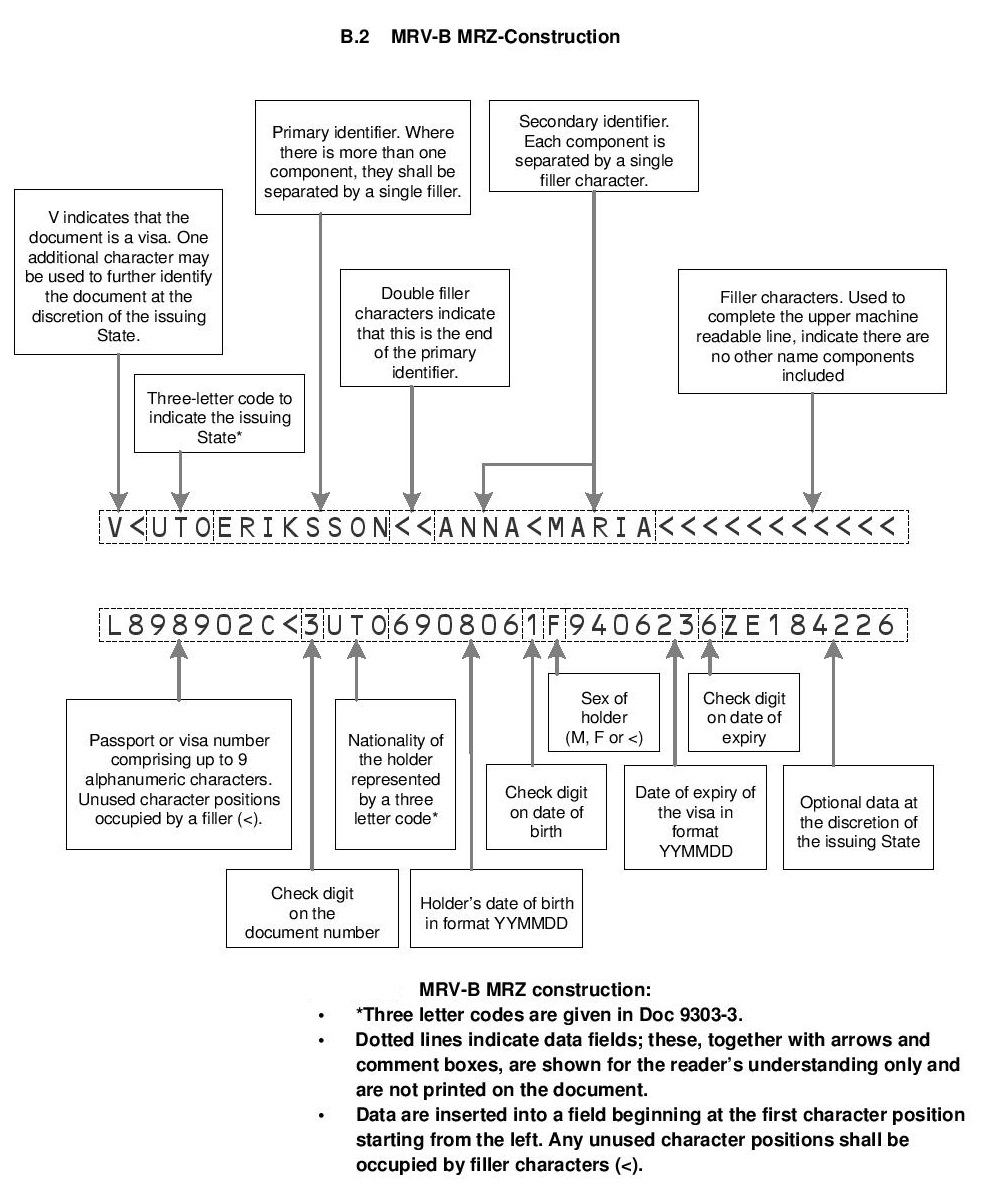
Parser¶
The MRZ parser is closed source and based on an open source project at https://github.com/DoubangoTelecom/ultimateMRZ-SDK/tree/master/samples/c++/parser. This sample application uses regular expressions which means you can easily migrate the code to C#, Python or Java (no change to the regex).
If you’re dealing with non-standard formats and struggling to write the right regular expressions then, don’t hesitate to contact us via our dev-group and we’ll help you and update the SDK to support it.
Here are some samples we’ll use in the next sections:
TD1 |
I<UTOD231458907<<<<<<<<<<<<<<< |
TD2 |
I<UTOERIKSSON<<ANNA<MARIA<<<<<<<<<<< |
TD3 |
P<UTOERIKSSON<<ANNA<MARIA<<<<<<<<<<<<<<<<<<< |
MRVA |
V<UTOERIKSSON<<ANNA<MARIA<<<<<<<<<<<<<<<<<<< |
MRVB |
V<UTOERIKSSON<<ANNA<MARIA<<<<<<<<<<< |
Determine the document type¶
The MRZ lines (array of strings) returned by the SDK are sorted from top to bottom.
The first operation is to deteermine the document type. You can determine the type using a single line of code:
const MRZ_DOCUMENT_TYPE type = (lines.size() == 3 && lines.front().size() == 30) ? MRZ_DOCUMENT_TYPE_TD1 : ((lines.front().size() == 44 && lines.size() == 2) ? (lines.front()[0] == 'P' ? MRZ_DOCUMENT_TYPE_TD3 : MRZ_DOCUMENT_TYPE_MRVA) : ((lines.front().size() == 36 && lines.size() == 2) ? (lines.front()[0] == 'V' ? MRZ_DOCUMENT_TYPE_MRVB : MRZ_DOCUMENT_TYPE_TD2) : MRZ_DOCUMENT_TYPE_UNKNOWN));
Parsing TD1 format¶
TD1 format has 3 lines, each has 30 characters.
Line 1 (TD1#1)¶
Regular expression (TD1#1)¶
Regular expression |
|
([A|C|I][A-Z0-9<]{1})([A-Z]{3})([A-Z0-9<]{9})([0-9]{1})([A-Z0-9<]{15}) |
|
Group #1 |
Document type. A, C or I as the first character. |
Group #2 |
3 letters country code. |
Group #3 |
Document number, up to 9 alphanumeric characters. |
Group #4 |
Check digit on the document number. |
Group #5 |
Optional data at the discretion of the issuing state. |
Sample result (TD1#1)¶
Data |
|
I<UTOD231458907<<<<<<<<<<<<<<< |
|
Group #1 |
I< |
Group #2 |
UTO |
Group #3 |
D23145890 |
Group #4 |
7 |
Group #5 |
<<<<<<<<<<<<<<< |
Line 2 (TD1#2)¶
Regular expression (TD1#2)¶
Regular expression |
|
([0-9]{6})([0-9]{1})([M|F|X|<]{1})([0-9]{6})([0-9]{1})([A-Z]{3})([A-Z0-9<]{11})([0-9]{1}) |
|
Group #1 |
Holder’s date of birth in format YYMMDD. |
Group #2 |
Check digit on the date of birth. |
Group #3 |
Sex of holder. |
Group #4 |
Date of expiry of the document in format YYMMDD. |
Group #5 |
Check digit on date of expiry. |
Group #6 |
Nationality of the holder represented by a three-letter code. |
Group #7 |
Optional data at the discretion of the issuing state. |
Group #8 |
Overall check digit for upper and middle MRZ lines. |
Sample result (TD1#2)¶
Data |
|
7408122F1204159UTO<<<<<<<<<<<6 |
|
Group #1 |
740812 |
Group #2 |
2 |
Group #3 |
F |
Group #4 |
120415 |
Group #5 |
9 |
Group #6 |
UTO |
Group #7 |
<<<<<<<<<<< |
Group #8 |
6 |
Parsing TD2 format¶
TD2 format has 2 lines, each has 36 characters.
Line 1 (TD2#1)¶
Regular expression (TD2#1)¶
Regular expression |
|
([A|C|I][A-Z0-9<]{1})([A-Z]{3})([A-Z0-9<]{31}) |
|
Group #1 |
Document type. A, C or I as the first character. |
Group #2 |
3 letters country code. |
Group #3 |
Primary Identifier. |
Sample result (TD2#1)¶
Data |
|
I<UTOERIKSSON<<ANNA<MARIA<<<<<<<<<<< |
|
Group #1 |
I< |
Group #2 |
UTO |
Group #3 |
ERIKSSON, ANNA MARIA |
Line 2 (TD2#2)¶
Regular expression (TD2#2)¶
Regular expression |
|
([A-Z0-9<]{9})([0-9]{1})([A-Z]{3})([0-9]{6})([0-9]{1})([M|F|X|<]{1})([0-9]{6})([0-9]{1})([A-Z0-9<]{7})([0-9]{1}) |
|
Group #1 |
Document number, up to 9 alphanumeric characters. |
Group #2 |
Check digit on document number. |
Group #3 |
Nationality. 3 letters country code. |
Group #4 |
Holder’s date of birth. |
Group #5 |
Check digit on the date of birth. |
Group #6 |
Sex of holder. |
Group #7 |
Date of expiry of the document. |
Group #8 |
Check digit on the date of expiry. |
Group #9 |
Optional data at the discretion of the issuing state. |
Group #10 |
Overall check digit |
Sample result (TD2#2)¶
Data |
|
D231458907UTO7408122F1204159<<<<<<<6 |
|
Group #1 |
D23145890 |
Group #2 |
7 |
Group #3 |
UTO |
Group #4 |
740812 |
Group #5 |
2 |
Group #6 |
F |
Group #7 |
120415 |
Group #8 |
9 |
Group #9 |
<<<<<<< |
Group #10 |
6 |
Parsing TD3 format¶
TD3 format has 2 lines, each has 44 characters.
Line 1 (TD3#1)¶
Regular expression (TD3#1)¶
Regular expression |
|
(P[A-Z0-9<]{1})([A-Z]{3})([A-Z0-9<]{39}) |
|
Group #1 |
Document type. P as the first character. |
Group #2 |
3 letters country code. |
Group #3 |
Primary Identifier. |
Sample result (TD3#1)¶
Data |
|
P<UTOERIKSSON<<ANNA<MARIA<<<<<<<<<<<<<<<<<<< |
|
Group #1 |
P< |
Group #2 |
UTO |
Group #3 |
ERIKSSON, ANNA MARIA |
Line 2 (TD3#2)¶
Regular expression (TD3#2)¶
Regular expression |
|
([A-Z0-9<]{9})([0-9]{1})([A-Z]{3})([0-9]{6})([0-9]{1})([M|F|X|<]{1})([0-9]{6})([0-9]{1})([A-Z0-9<]{14})([0-9]{1})([0-9]{1}) |
|
Group #1 |
Document number, up to 9 alphanumeric characters. |
Group #2 |
Check digit on document number. |
Group #3 |
Nationality. 3 letters country code. |
Group #4 |
Holder’s date of birth. |
Group #5 |
Check digit on the date of birth. |
Group #6 |
Sex of holder. |
Group #7 |
Date of expiry of the document. |
Group #8 |
Check digit on the date of expiry. |
Group #9 |
Optional data at the discretion of the issuing state. |
Group #10 |
Check digit on the optional data. |
Group #11 |
Overall check digit. |
Sample result (TD3#2)¶
Data |
|
L898902C36UTO7408122F1204159ZE184226B<<<<<10 |
|
Group #1 |
L898902C3 |
Group #2 |
6 |
Group #3 |
UTO |
Group #4 |
740812 |
Group #5 |
2 |
Group #6 |
F |
Group #7 |
120415 |
Group #8 |
9 |
Group #9 |
ZE184226B<<<<< |
Group #10 |
1 |
Group #11 |
0 |
Parsing MRVA format¶
MRVA format has 2 lines, each has 44 characters.
Line 1 (MRVA#1)¶
Regular expression (MRVA#1)¶
Regular expression |
|
(V[A-Z0-9<]{1})([A-Z]{3})([A-Z0-9<]{39}) |
|
Group #1 |
Document type. V as the first character. |
Group #2 |
3 letters country code. |
Group #3 |
Primary Identifier. |
Sample result (MRVA#1)¶
Data |
|
V<UTOERIKSSON<<ANNA<MARIA<<<<<<<<<<<<<<<<<<< |
|
Group #1 |
V< |
Group #2 |
UTO |
Group #3 |
ERIKSSON, ANNA MARIA |
Line 2 (MRVA#2)¶
Regular expression (MRVA#2)¶
Regular expression |
|
([A-Z0-9<]{9})([0-9]{1})([A-Z]{3})([0-9]{6})([0-9]{1})([M|F|X|<]{1})([0-9]{6})([0-9]{1})([A-Z0-9<]{16}) |
|
Group #1 |
Document number, up to 9 alphanumeric characters. |
Group #2 |
Check digit on document number. |
Group #3 |
Nationality. 3 letters country code. |
Group #4 |
Holder’s date of birth. |
Group #5 |
Check digit on the date of birth. |
Group #6 |
Sex of holder. |
Group #7 |
Date of expiry of the document. |
Group #8 |
Check digit on the date of expiry. |
Group #9 |
Optional data at the discretion of the issuing state. |
Sample result (MRVA#2)¶
Data |
|
L8988901C4XXX4009078F96121096ZE184226B<<<<<< |
|
Group #1 |
L8988901C |
Group #2 |
4 |
Group #3 |
XXX |
Group #4 |
400907 |
Group #5 |
8 |
Group #6 |
F |
Group #7 |
961210 |
Group #8 |
9 |
Group #9 |
6ZE184226B<<<<<< |
Parsing MRVB format¶
MRVB format has 2 lines, each has 36 characters.
Line 1 (MRVB#1)¶
Regular expression (MRVB#1)¶
Regular expression |
|
(V[A-Z0-9<]{1})([A-Z]{3})([A-Z0-9<]{31}) |
|
Group #1 |
Document type. V as the first character. |
Group #2 |
3 letters country code. |
Group #3 |
Primary Identifier. |
Sample result (MRVB#1)¶
Data |
|
V<UTOERIKSSON<<ANNA<MARIA<<<<<<<<<<< |
|
Group #1 |
V< |
Group #2 |
UTO |
Group #3 |
ERIKSSON, ANNA MARIA |
Line 2 (MRVB#2)¶
Regular expression (MRVB#2)¶
Regular expression |
|
([A-Z0-9<]{9})([0-9]{1})([A-Z]{3})([0-9]{6})([0-9]{1})([M|F|X|<]{1})([0-9]{6})([0-9]{1})([A-Z0-9<]{8}) |
|
Group #1 |
Document number, up to 9 alphanumeric characters. |
Group #2 |
Check digit on document number. |
Group #3 |
Nationality. 3 letters country code. |
Group #4 |
Holder’s date of birth. |
Group #5 |
Check digit on the date of birth. |
Group #6 |
Sex of holder. |
Group #7 |
Date of expiry of the document. |
Group #8 |
Check digit on the date of expiry. |
Group #9 |
Optional data at the discretion of the issuing state. |
Sample result (MRVB#2)¶
Data |
|
L8988901C4XXX4009078F9612109<<<<<<<< |
|
Group #1 |
L8988901C |
Group #2 |
4 |
Group #3 |
XXX |
Group #4 |
400907 |
Group #5 |
8 |
Group #6 |
F |
Group #7 |
961210 |
Group #8 |
9 |
Group #9 |
<<<<<<<< |
Data validation¶
What is nice with the MRZ / MRTD specifications is that they contain different check digits to make sure that the most important fields (document number, expiry date, date of birth…) are valid. We’ll explain how the validation is done in the next sections.
The code to validate the MRZ data is closed source and based on open source code at https://github.com/DoubangoTelecom/ultimateMRZ-SDK/tree/master/samples/c++/validation.
A check digit consists of a single digit computed from the other digits in a series. Check digits in the MRZ are calculated on specified numerical data elements in the MRZ. The check digits permit readers to verify that data in the MRZ is correctly interpreted.
- A special check digit calculation has been adopted for use in MRTDs. The check digits shall be calculated on modulus 10 with a continuously repetitive weighting of 731 731 …, as follows:
Step 1. Going from left to right, multiply each digit of the pertinent numerical data element by the weighting figure appearing in the corresponding sequential position.
Step 2. Add the products of each multiplication.
Step 3. Divide the sum by 10 (the modulus).
Step 4. The remainder shall be the check digit.
For data elements in which the number does not occupy all available character positions, the symbol < shall be used to complete vacant positions and shall be given the value of zero for the purpose of calculating the check digit.
When the check digit calculation is applied to data elements containing alphabetic characters, the characters A to Z shall have the values 10 to 35 consecutively, as follows:
A |
10 |
B |
11 |
C |
12 |
D |
13 |
E |
14 |
F |
15 |
G |
16 |
H |
17 |
I |
18 |
J |
19 |
K |
20 |
L |
21 |
M |
22 |
N |
23 |
O |
24 |
P |
25 |
Q |
26 |
R |
27 |
S |
28 |
T |
29 |
U |
30 |
V |
31 |
W |
32 |
X |
33 |
Y |
34 |
Z |
35 |
Next sections explain how to implement the above algorithm using C++. The entire code could be found at https://github.com/DoubangoTelecom/ultimateMRZ-SDK/blob/master/samples/c++/validation/main.cxx and it’s used in the validation sample application.
The SDK itself doesn’t contain the validation code for the simple reason that we want it to be generic to work with any MRZ format even if the data is malformed or non-standard.
Local variables and macros¶
- Weighting:
static const int __Weights[] = { 7, 3, 1 };
- Mapped values:
static std::map<char, int> __MappedValues; const std::string charset = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ"; for (int i = 0; i < static_cast<int>(charset.size()); ++i) { __MappedValues[charset[i]] = i; } __MappedValues['<'] = 0;
- Weighted sum:
#define MRZ_COMPUTE_WEIGHTED_SUM(_line_, _start_, _end_, w) { \ for (size_t i = _start_, j = w; i <= _end_; ++i, ++j) { \ sum += __MappedValues[(_line_)[i]] * __Weights[j % 3]; \ } \ }
- Validity check:
#define MRZ_CHECK_VALIDITY(_line_, _start_, _end_, _check_, _ret_) { \ const std::string __line__ = (_line_); \ int sum = 0; \ MRZ_COMPUTE_WEIGHTED_SUM(__line__, _start_, _end_, 0); \ _ret_ = ((sum % 10) == __MappedValues[__line__[_check_]]); \ }
Validating TD1 format¶
bool documentNumber, dateOfBirth, dateOfExpiry, upperAndMiddleLines;
MRZ_CHECK_VALIDITY(lines[0], 5, 13, 14, documentNumber);
MRZ_CHECK_VALIDITY(lines[1], 0, 5, 6, dateOfBirth);
MRZ_CHECK_VALIDITY(lines[1], 8, 13, 14, dateOfExpiry);
int sum = 0;
MRZ_COMPUTE_WEIGHTED_SUM(lines[0], 5, 29, 0);
MRZ_COMPUTE_WEIGHTED_SUM(lines[1], 0, 6, 25);
MRZ_COMPUTE_WEIGHTED_SUM(lines[1], 8, 14, 32);
MRZ_COMPUTE_WEIGHTED_SUM(lines[1], 18, 28, 43);
upperAndMiddleLines = (sum % 10) == __MappedValues[lines[1][29]];
Validating TD2 format¶
bool documentNumber, dateOfBirth, dateOfExpiry, composite;
MRZ_CHECK_VALIDITY(lines[1], 0, 8, 9, documentNumber);
MRZ_CHECK_VALIDITY(lines[1], 13, 18, 19, dateOfBirth);
MRZ_CHECK_VALIDITY(lines[1], 21, 26, 27, dateOfExpiry);
int sum = 0;
MRZ_COMPUTE_WEIGHTED_SUM(lines[1], 0, 9, 0);
MRZ_COMPUTE_WEIGHTED_SUM(lines[1], 13, 19, 10);
MRZ_COMPUTE_WEIGHTED_SUM(lines[1], 21, 34, 17);
composite = (sum % 10) == __MappedValues[lines[1][35]];
Validating TD3 format¶
bool passportNumber, dateOfBirth, dateOfExpiry, personalNumber, composite;
MRZ_CHECK_VALIDITY(lines[1], 0, 8, 9, passportNumber);
MRZ_CHECK_VALIDITY(lines[1], 13, 18, 19, dateOfBirth);
MRZ_CHECK_VALIDITY(lines[1], 21, 26, 27, dateOfExpiry);
MRZ_CHECK_VALIDITY(lines[1], 28, 41, 42, personalNumber);
int sum = 0;
MRZ_COMPUTE_WEIGHTED_SUM(lines[1], 0, 9, 0);
MRZ_COMPUTE_WEIGHTED_SUM(lines[1], 13, 19, 10);
MRZ_COMPUTE_WEIGHTED_SUM(lines[1], 21, 42, 17);
composite = (sum % 10) == __MappedValues[lines[1][43]];
Validating MRVA and MRVB formats¶
bool documentNumber, dateOfBirth, dateOfExpiry;
MRZ_CHECK_VALIDITY(lines[1], 0, 8, 9, documentNumber);
MRZ_CHECK_VALIDITY(lines[1], 13, 18, 19, dateOfBirth);
MRZ_CHECK_VALIDITY(lines[1], 21, 26, 27, dateOfExpiry);
